Page: 1
/ 8
Total 39 questions
Note: This question Is part of a series of questions that use the same or similar answer choice. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series.
Information and details provided In a question apply only to that question.
You build a model that uses xyz regression.
You need to estimate a model that predicts a binary variable.
Which function should you use?
- A. rxPredict
- B. rxLogit
- C. Summary
- D. rxLinMod
- E. rxTweedie
- F. stepAic
- G. rxTransform
- H. rxDataStep
Answer : B
Explanation: https://docs.microsoft.com/en-us/r-server/r/how-to-revoscaler-logistic- regression
You are running a parallel function that uses the following R code segment. (Line numbers are included for reference only.)

You need to complete the R code. The solution must support chunking.
- A. rxBTrees
- B. rxExec
- C. rxDForest
- D. rxDTree
Answer : C
You have a dataset that has multiple blocks and only numeric variables.
You are computing in a local compute context.
You plan to lag a variable named x to create a new variable named x_lagged by using a transform function. You will create a new element in the output of the function.
You need to minimize the number of missing values.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Assign a value to the first value of x_lagged in the current block.
- B. Use rxSet to store the last value of x_lagged in the current block.
- C. Use rxSet to store the last value of x in the current block.
- D. Use rxGet to retrieve the first value of x in the next block to be processed.
- E. Use rxGet to retrieve a value stored in processing of the prior block.
Answer : A,C,D
You need to run a larger data tree model by using rsDForest. The model must use cross validation.
Which rxDForest option should you use?
- A. maxSurrogate
- B. maxNumBins
- C. maxDepth
- D. maxCompete
- E. xVal
Answer : E
Explanation: https://docs.microsoft.com/en-us/r-server/r/how-to-revoscaler-decision-tree
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
Start of repeated scenario -
You are developing a Microsoft R Open solution that will leverage the computing power of the database server for some of your datasets.
You are performing feature engineering and data preparation for the datasets.
The following is a sample of the dataset.
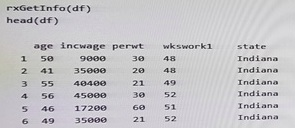
End of repeated scenario -
You need to sort the data from the dataset sample and to remove duplicates by using wkswork1.
Which R code segment should you use? to answer, select the appropriate options in the answer area.
Note: Each correct selection is worth one point.

Answer :


